To understand how genetic mutations lead to disease, it is necessary to understand the basics on how information flows from genes to proteins.
The Central Dogma of biology:
Genes contain the information to build the proteins that operate the cell. This building process is done in 2 steps: Transcription and Translation.
The genetic code:
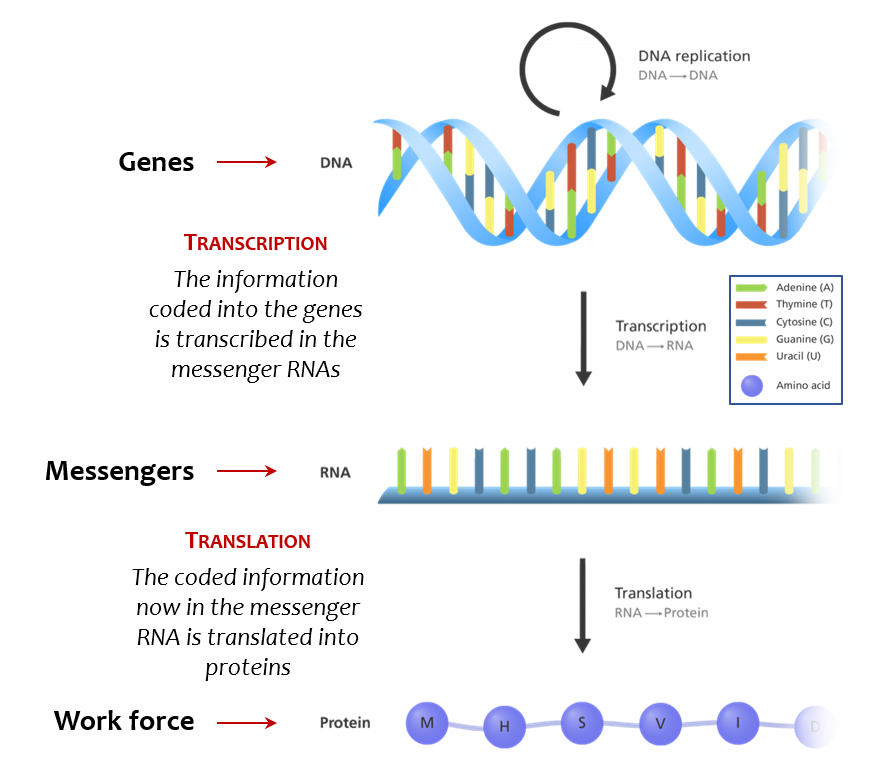
DNA to RNA
The information contained in our genome – our DNA – is written in a 4-unit code. These 4 units, as mentioned above in the drawing, are Adenine A, Thymine T, Guanine G, and Cytosine C.
A gene is a unique linear sequence of “DNA” made of these 4 units; for example, a stretch of the FKRP gene looks like this:
…c t g g t c c t c t t c t a t g t c t c g t g g c t g…
where a “c” (cytosine) is bound to a “t” (thymine) that is bound to a “g” (guanine) …
The information to build proteins is contained in our genes, and our genes are contained into our DNA, which can be compared to a library of information. The “messenger RNA” carried the blueprints of proteins from the “library” to the site of protein production. To faithfully carry the blueprint information around the cell, RNAs are made of a 4-unit code similar to the one found in our gene. Transcription is the process of copying the coded blueprint of proteins from the DNA/gene onto the RNA. And so, the sequence of an RNA looks strangely similar to the sequence of the gene.
- Gene: …c t g g t c c t c t t c t a t g t c t c g t g g c t g…
- RNA: …c u g g u c c u c u u c u a u g u c u c g u g g c u g…
RNA to Protein
While DNA (genes) and RNA (messengers) use similar codes made of 4 units (called nucleotides), proteins are built very differently. Proteins are built using 20 units called amino-acids. Translation is the process of converting the sequence of a messenger – carrying the gene’s information based on a 4-nucleotide code – into a protein sequence made of 20 amino-acids.
To guide this translation, cells follow the genetic code. According to the genetic code, the genetic information is organized in triplets of nucleotides, and each triplet is translated into one amino-acid. Below is an illustration of the genetic code in action: the stretch of the FKRP RNA is being translated into the FKRP protein. The triplet “cug” codes for “L” or Leucine; the triplet “guc” codes for “V” or Valine… and so the FKRP protein is synthesized by binding the first amino-acid L to V that binds to another L, that binds to a F (Phenylalanine), …
- RNA: … c u g g u c c u c u u c u a u g u c u c g u g g c u g …
- Protein: L V L F Y V S W L
Importantly…
The 4 nucleotides, found in the genes, can combine in 64 triplets (called “codons” or unit of code). Because 61 of these “codons” code for the 20 amino-acids, each amino-acid is coded by several codons. For example, codons “CUA”, “CUC”, CUG”, and “CUU” code for the same amino-acid called “Leucine” or “L”. And, “GUA”, “GUC”, “GUG”, and “GUU” code for the same amino-acid called “Valine” or “V”.
Mutations and the limit of the genetic code:
Because it gives our genes the ability to neutralize changes that could lead to pathogenic mutations. In the sequence above, the first and third triplets in the sequence above, “cug” and “cuc” differ by the last letter but code for the same unit of protein called “L”. However the second and third triplets, “guc” and “cuc” also differ by one letter but code for 2 different amino-acids, “V” and “L”.
It is easy to see that if, by mistake (mutation), the first triplet “cug” were to become”cuc”, the protein would still be the same because “cug” and “cuc” code for the same amino-acid “L”. This kind of mutation (called synonymous mutation) has no consequence because of the flexibility of our coding system. In the other case, if, by mistake (mutation), the second triplet “guc” were to become”cuc”, the protein would not be the same because “guc” and “cuc” code for different amino-acids. This kind of mutation (called non-synonymous mutation) often leads to disease.
Wild type sequence:
- RNA: c u g g u c c u c
- Protein: L V L
Synonymous mutation (no consequence)
- RNA: c u c g u c c u c mutation: change from “g” to “c” in 1st triplet
- Protein: L V L Unchanged protein sequence
NON synonymous mutation (consequence):
- RNA: c u g c u c c u c nucleotide mutation from a “g” to “c” in 2nd triplet
- Protein: L L L Changed protein sequence